Can we always trust point cloud data?

Accuracy is a crucial concern when performing a 3D laser scanning survey. During more than ten years of serving on point cloud data processing, our customers always come up with the same question: “Can we maintain a level of accuracy bounded by a few millimetres?”. So far, we have finished thousands of projects with similar job specifications, and the answer is, of course, yes. However, our customers and our team always sit together and explore another question before starting the project, and the question is: “Can we trust the current point cloud data”?
In this post, we first discuss several facts related to point cloud inaccuracies that are acquired by modern laser scanners. Then we demonstrate some real-world case studies about information loss during the laser scanning process. Finally, we suggest the solution to overcome these limitations to avoid any expected risks that compromise the quality of the final products—3D models, CAD drawings, visualizations.
The reasons for inaccuracies in point cloud capturing.
Errors in point cloud data may occur due to several reasons. The first reason is the inherent capability of the laser scanner. All laser scanners—even the best ones—have a maximum level of accuracy, and this level depends on the distance we measure. For example, the error is around +/- 1mm for every distance of 10 meters. Thus, the further the distance we desire to estimate, the larger the error could be incurred.
The second reason that leads to point cloud inaccuracies is the failure in the registration process. The registration process is sensitive to the initial alignment of the point clouds to be registered and their overlapping. Therefore, improper initial alignment or low overlapping scans may significantly damage the quality of the registration.
The final reason for point cloud inaccuracies is error propagation. This class of error happens when we combine multiple point cloud scans. For instance, we have a collection of point cloud scans, and each scan has an error of +/- 1mm. Thus, each step away from the rooted scan will suffer an accumulated amount of errors equal to the sum of square error by each scan.
Although there are many errors caused by not strictly following the best practices in fieldwork scanning, they are outside the scope of this post, as here, we mainly desire to share our experience on back-office data processing. We intend to share the best practices on fieldwork scanning in a future post.
Case studies.
Case study 1.
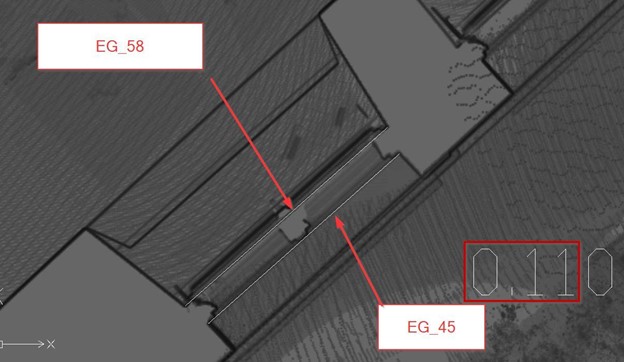
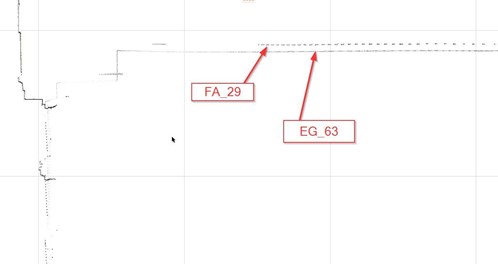
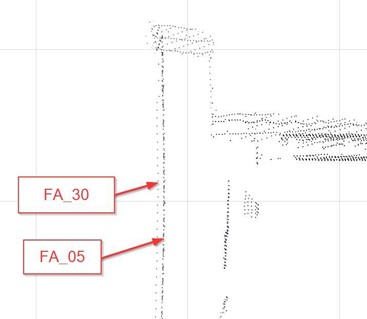
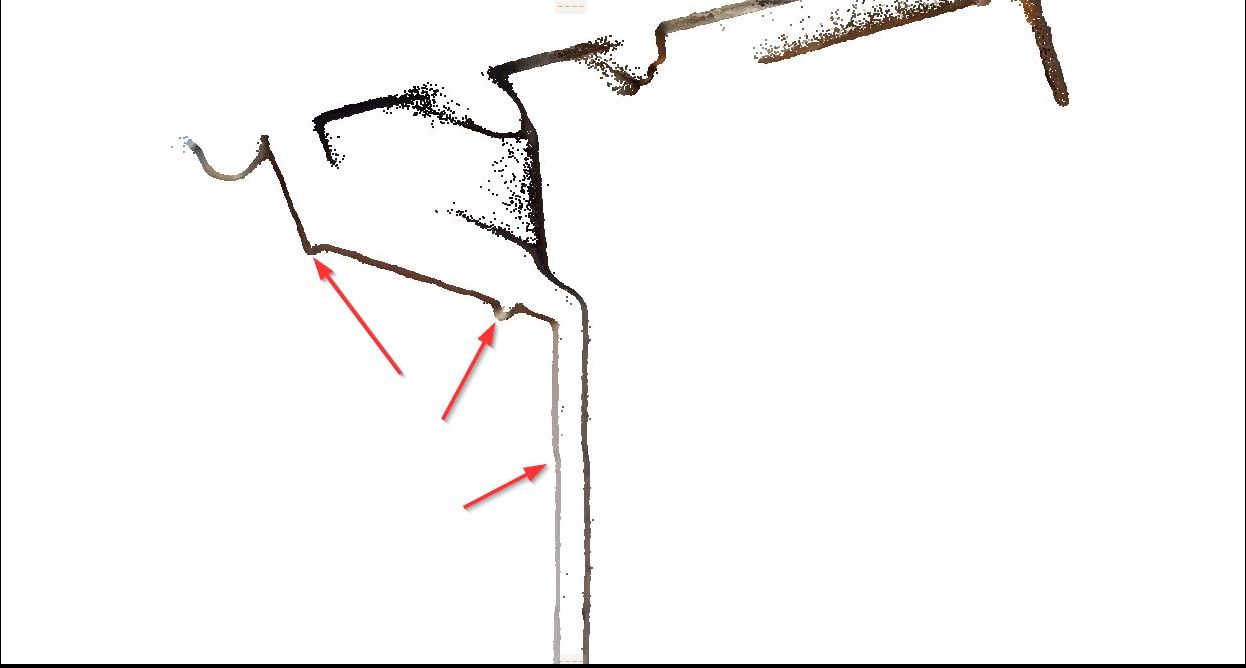
We describe the case study using a scan on the edge of a window—the edge divided the whole space into the inside half-space and outside half-space, as shown in Figure 1. We used some standard anchors as the reference points to assess the accuracy, and we found the deviation between the point cloud files of the outside half-space (FA_04) and the inside half-space (EG_64).
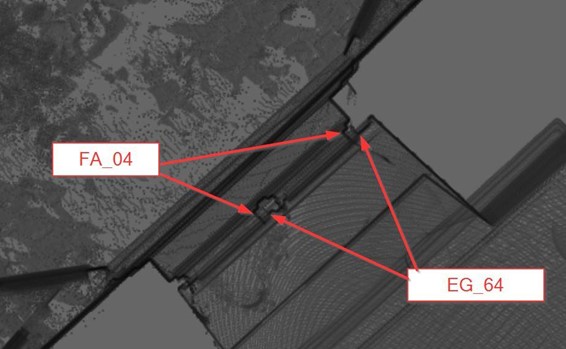
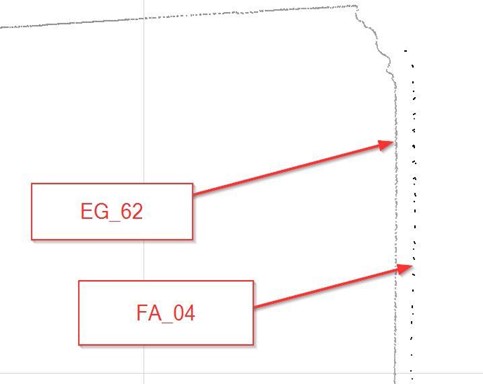
This deviation is about 40mm, but it is hard to identify. (if drawn according to the point cloud, the accuracy of 5mm does not hold true). The difference not only occurs between 2 point cloud files, but errors on nearby points are also detected in this example between—the file FA_04 and the file EG_62 in the figure below.
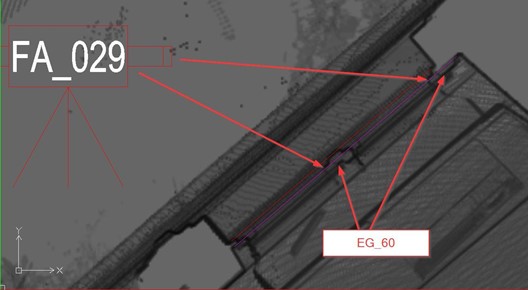
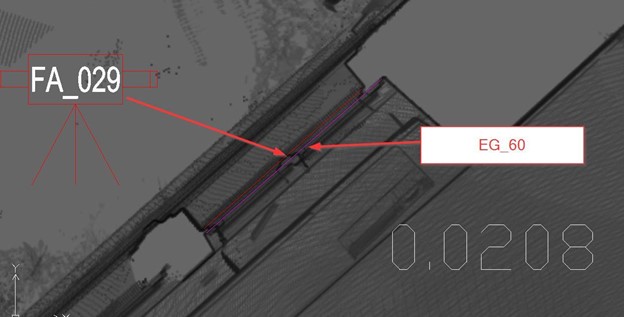
Similar deviation occurred between the file FA_029 and the file EG_60.
Case study 2.
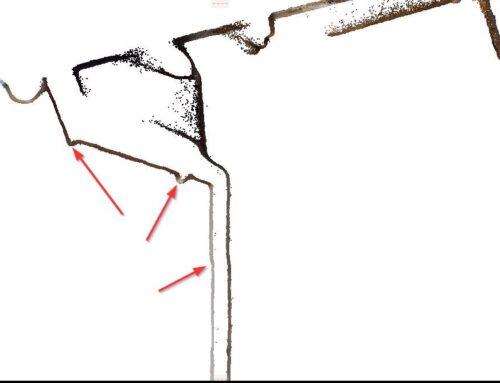
Overall inspection we can find the door thickness left position is problematic compared to the same type of door on the right?

Zoom in on the left position
Zoom in on the right position
We figure out a huge deviation up to 90 mm. (if we draw according to point cloud, the accuracy of 5mm no longer makes sense). We further checked the vertical surface and it is clearly showed the difference in point cloud inside and outside space.
And many other deviations in different locations.
The Solution
Similar to other data processing pipelines, point cloud processing also deals with errors, and this phenomenon is normal. The important thing is how we address these kinds of information loss efficiently. Some argue that they could save time and cost for a customer by following a trivial workflow — they fill the erroneous data with the average values from its neighbouring points. Although this approach may save the processing time, the quality is severely sacrificed. This level of accuracy may be acceptable for specific purposes, including showcase, animation for advertising. However, it is not acceptable in critical domains such as construction and architecture.

We adopt a more rigorous verification process from the very beginning of the point cloud processing pipeline to overcome these issues. We are aware that the verification process may cause some overhead time. However, this is how we bring the highest quality to thousands of projects for customers worldwide. In particular, we integrated our workflow with the Kanban principle—the principle applied by Toyota corporation to maintain the consistency in the quality of their services. More precisely, at the beginning of the process, we get quick “feedback loops” with our customers until both of us “start to trust on our point cloud data”. Although we have the quality team to check for the deliveries, the data we use must be correct from the beginning, and that makes us stand out as one of the leading companies in point cloud data processing for more than ten years in the global market.

Take away
1/ We accept the fact that point clouds may have many deviations from reality, sometimes massive deviations.
2/ Some errors are notoriously hard to detect, and thus requiring a lot of know-how and hands-on experience in various complex projects.
3/ For this reason, verification is a must-have step in point cloud processing to make the data reliable before any further processing
Frequently Asked Questions
Can point cloud data be inaccurate?
Yes. Point cloud data can contain inaccuracies caused by scanner hardware limitations, environmental conditions during scanning, insufficient scan overlap, or errors introduced during the registration process. Understanding the source of error is the first step in managing it.
What causes errors in laser scan data?
The main causes are: scanner measurement limits (typically +/- 1mm per 10 meters of distance), registration failures from insufficient overlap between scan positions, and error propagation when merging multiple scans. Each additional scan position can accumulate small errors that compound across the full dataset.
What is scan registration error?
Scan registration error occurs when individual scan positions are not aligned correctly during the merging process. Poor target placement, insufficient overlap, or weak reference geometry can all cause registration drift – resulting in a point cloud that appears continuous but contains geometric inconsistencies that carry through into the BIM model.
How do inaccuracies in point cloud data affect BIM models?
Inaccuracies in the source point cloud can cause deviations of 40mm or more in the final model. For construction and architecture projects requiring high precision, even small errors affect coordination, documentation, and the reliability of downstream decisions based on the model.
How does VMTS verify point cloud quality before modeling?
VMTS verifies point cloud quality at the start of every project before modeling begins. This includes checking registration accuracy, scan coverage, noise levels, and data completeness. Issues are flagged and resolved with the client before any BIM work proceeds – preventing errors from being modeled in rather than caught later.
What are the best practices for verifying point cloud accuracy?
Best practices include: initial verification of the full dataset before processing begins, checking registration reports for residual errors, engaging in fast feedback loops with the scanning team to resolve ambiguities, and maintaining documented QC records throughout the project. A reliable BIM provider should be able to explain what was checked and why.
Nguyen Huynh (Rainer)
")
About the Author:
Nguyen Huynh (Rainer) is Managing Director at VMT Solutions, specializing in Point Cloud to BIM workflows for surveying, planning, and engineering offices. He focuses on precise BIM models, clearly defined quality standards, and long-term technical partnerships.
Share This Story!
Related Posts


Recent Posts











We are proud to have
satisfied customers.
 Gerd Gindullis, Lecturer for digital as-built data capture at Aachen University of Applied Sciences, TerraMeta 3D Laser Service
Gerd Gindullis, Lecturer for digital as-built data capture at Aachen University of Applied Sciences, TerraMeta 3D Laser Service Stefan Schramm, Architekt Stefan Schramm
Stefan Schramm, Architekt Stefan Schramm„Your plans are perfect; I’ve never seen anything like this before. These are drawings of the highest quality, I must say. I want to express my sincere thanks once again for your work.“
 Endre Szokolai, Digitalplan-Szokolai
Endre Szokolai, Digitalplan-SzokolaiVMT modeled a large industrial building in 3D for our research project. We provided DWG plans to VMT, and they delivered a highly detailed model, including the building envelope, interior walls, openings, and stairs. We had previously contracted a German company for the same object, but unfortunately, it didn’t work out. I was relieved and pleased that VMT handled it so reliably. Thank you for the excellent work and the truly fair price!

Very reliable company, courteous staff, and top-quality work. Our plans were created quickly and accurately. Thank you for that. Highly recommended.

Excellent advice and high 3D modeling quality at a great price-performance ratio… What more could you want? I can highly recommend them…